


Inside CPU Accelerators and HBM Enable Faster and Smarter HPC and AI Features
We have now entered the interval when processor designers can leverage modular semiconductor manufacturing capabilities to rush frequently carried out operations (paying homage to small tensor operations) and offload a variety of housekeeping duties (paying homage to copying and zeroing memory) to devoted on-chip accelerators. The thought is to have software program program make the {{hardware}} work smarter. CPU designers may even incorporate high-bandwidth memory (HBM) modules to dramatically enhance the amount of data per second which may be supplied to these accelerated processor cores. Due to this these modular processors can work every faster and smarter as additional of the accelerated cores could also be saved busy processing info.
The know-how Intel is delivering inside the accelerator engines utilized in 4th Gen Intel® Xeon® processors shows an element transition as they’re now delivering a choice of accelerator know-how to prospects. With the introduction of the HBM-enabled Intel® Xeon® CPU Max Sequence processors, Intel is now uniquely positioned to show some great benefits of accelerated processor cores all through every kind of AI and HPC data-intensive workloads. The benchmark outcomes are compelling.[1]
HPC and AI clients is likely to be notably inside the accelerated capabilities of the Intel® Superior Matrix Extensions (Intel® AMX) and the Intel® Data Streaming Accelerator (Intel® DSA).
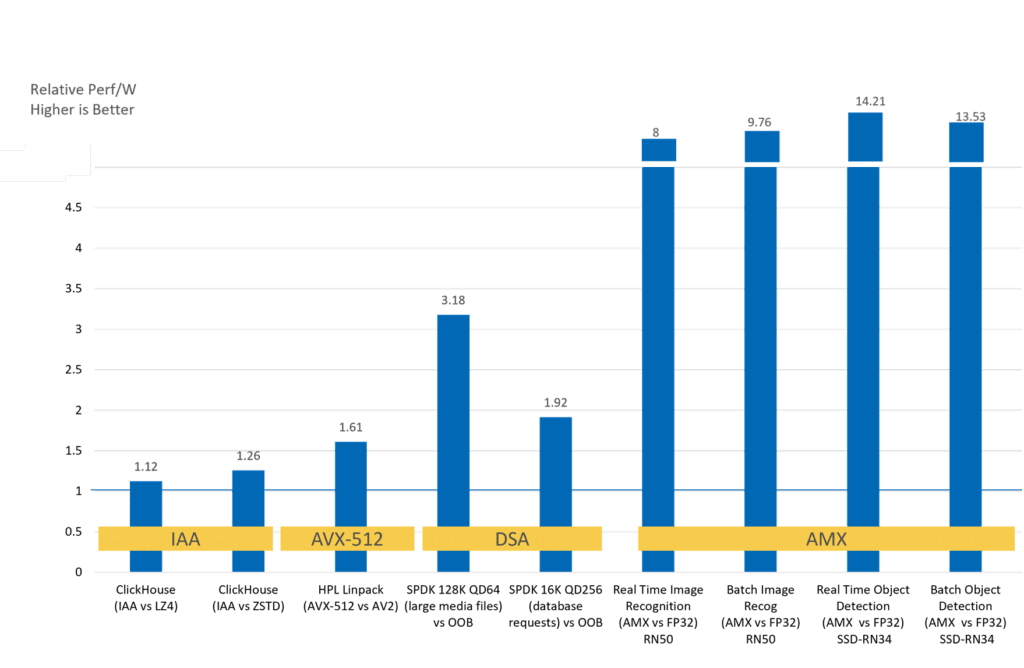
- Intel DSA: Intel benchmarks for the DSA vary in keeping with workload and operation carried out. Speedups embody faster AI teaching by having the DSA zero memory inside the kernel, elevated IOP/s/core by offloading CRC expertise all through storage operations, and naturally, MPI speedups that embody bigger throughput for shmem info copies. As an illustration, Intel quotes a 1.7× enhance in IOP/s value for giant sequential packet reads when using DSA compared with using the Intel® Intelligent Storage Acceleration Library with out DSA.[2]
- Intel AMX: Intel AMX delivers 3× to 10× bigger inference and training effectivity versus the sooner expertise on AI workloads that use bint8 and bfloat16 matrix operations. [3] [4]
HPC architects and cloud clients may additionally have an curiosity inside the effectivity per watt constructive components equipped by these on-chip accelerators.
Intel AMX, Intel DSA, and on-chip HBM mirror the flexibility of a design methodology that makes use of modular semiconductor establishing blocks (Decide 1). Chip modularity cannot be added in isolation. Along with the obligatory manufacturing performance, this modularity moreover requires a scalability on-chip communications materials such as a result of the Intel Xeon Scalable processor mesh materials.
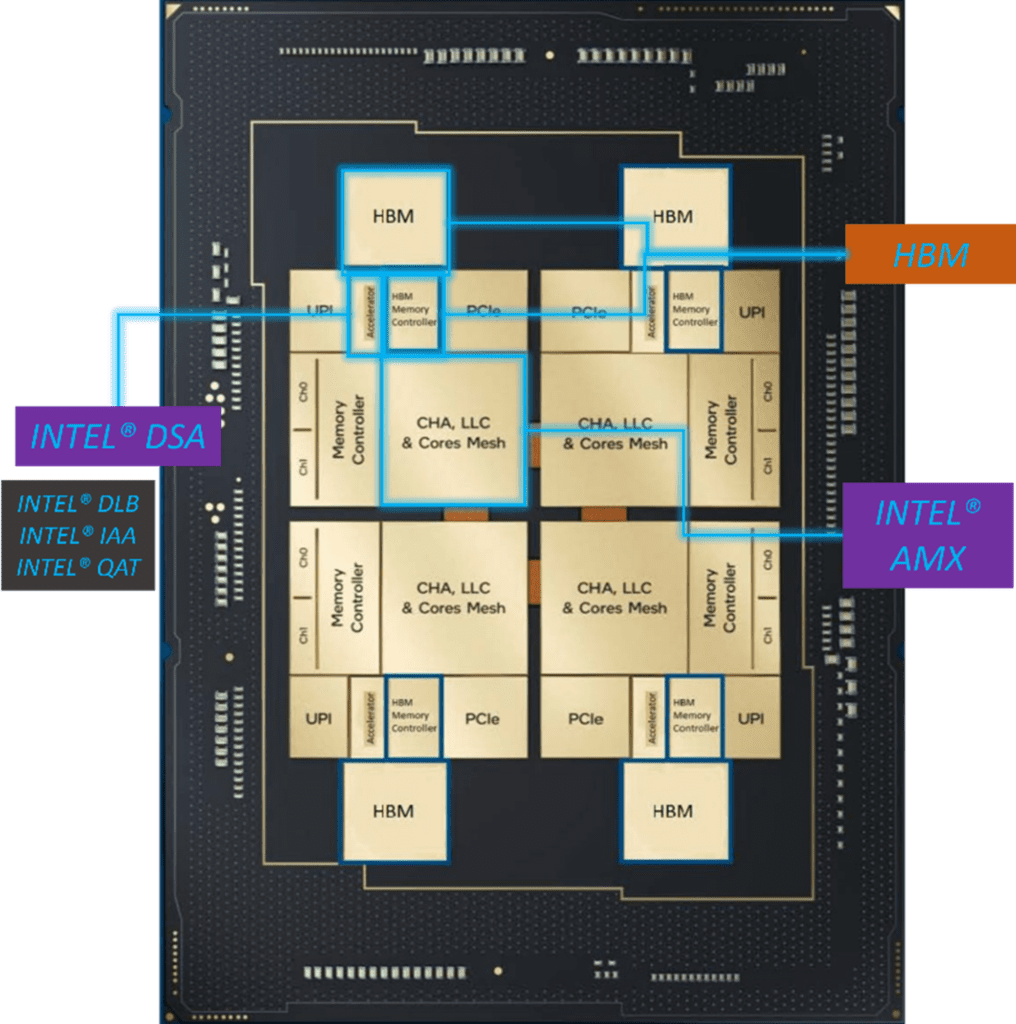
Transitioning to modular {{hardware}} design moreover requires that the supporting software program program ecosystem transparently permit utilizing the choices of the modules and accelerators. In some other case, software program program builders will develop into overwhelmed with having to help the combinatorics of all attainable on-chip modules and accelerators.
Matching software program program performance to {{hardware}} modularity explains why Intel (a semiconductor manufacturing agency) has invested extensively in oneAPI and an open ecosystem of libraries and standards-based software program program components. The Intel AMX extensions are transparently accessible from widespread libraries and functions along with TensorFlow and PyTorch. Intel DSA engine could also be accessed by the use of the IDXD kernel driver or Data Plane Enchancment Gear (DPDK) supported drivers. Newest Linux kernels already help DSA for operations paying homage to zeroing memory. The open-source libfabric library moreover makes use of the Intel DSA accelerator as does Intel® MPI.[5]
Intel DSA is a high-performance info copy that can be, importantly, an info transformation accelerator. It is designed to optimize streaming info movement and transformation operations which is likely to be frequent in high-performance storage, networking, persistent memory, and quite a few info processing functions.
The target of the accelerator is to produce bigger basic system effectivity for workloads that include quite a few info movement and transformation operations by releasing CPU cycles to hold out higher-level capabilities (Decide 2). The facility to hold out info transformation operations makes the Intel DSA accelerator a way more succesful accelerator than a straightforward DMA offload engine. Widespread Intel DSA operations embody zeroing memory; producing and testing CRC checksums; and performing Data Integrity Space (DIF) calculations to help storage and networking functions — all at very extreme tempo.

GPUs are well-known for accelerating small matrix operations and providing decreased precision arithmetic to rush up some AI workloads. Frequent machine finding out functions paying homage to TensorFlow and PyTorch make it simple to make use of those capabilities on a GPU.
Intel launched Intel AMX as a built-in accelerator to boost the effectivity of deep-learning teaching and inference on the CPU. Merely as with a GPU, these Intel AMX capabilities could also be accessed from widespread AI libraries and functions.
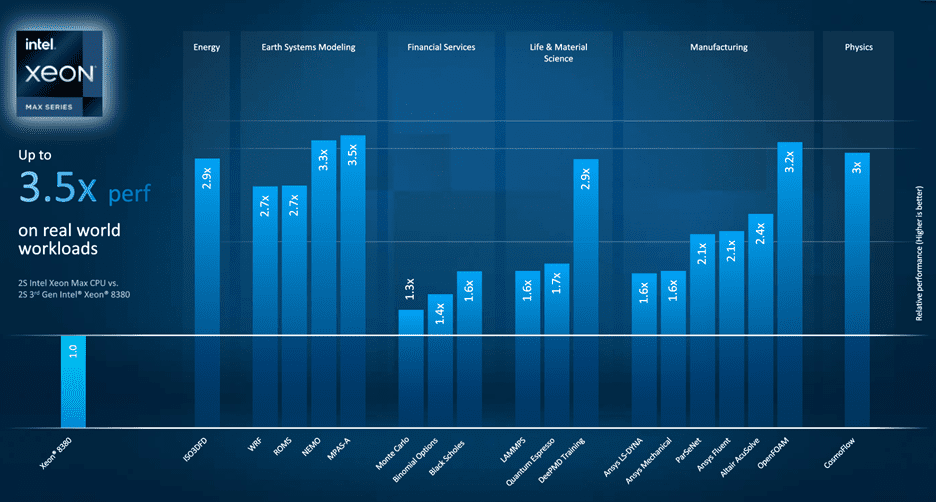
Lisa Spelman, Intel firm vice chairman and fundamental supervisor of Intel Xeon merchandise, highlighted the benefits in a present March 2023 investor webinar by noting that in a head-to-head opponents between a 48-core 4th Gen Intel Xeon and a 48-core 4th Gen AMD Epyc CPU, the 4th Gen Xeon delivered a imply effectivity obtain of 4 events the opponents’s effectivity on a broad set of deep-learning workloads.[7] (See Decide 4 underneath for additional effectivity per watt benchmark outcomes and totally different outcomes reported on the web.)
Along with elevated utility effectivity, accelerators may even ship dramatic power benefits. Maximizing effectivity for every watt of power utilized is a major concern at HPC and cloud info services across the globe. Evaluating the relative effectivity per watt on a 4th gen Intel Xeon processor working accelerated vs. non-accelerated software program program reveals an enormous effectivity per watt revenue — significantly for Intel AMX accelerated workloads.
HBM is a gateway know-how to faster time-to-solution with real-world benefits. Whereas the promise of peak effectivity might entice many with trillions of operations per second (TFlop/s), the reality is that exact effectivity for a lot of functions in the long run depends on the memory subsystem. Primarily based on the HBM2e specification, a single stack can ship as a lot as 307 GB/s, nevertheless some producers already exceed this.[9] The model new Intel Xeon Max processors can discover larger than 16 GB/s of HBM memory functionality per core with out having to drop the core rely. This may increasingly equate to significantly faster time to unravel on many workloads (Decide 4).
Memory is significant to effectivity, which is why every the HBM and DDR5 memory controllers are tightly built-in contained within the chip to permit them to work instantly with HBM and DDR5 with extreme effectivity. This leverages the mesh construction utilized by the Intel Xeon processors. Principally, each core and last-level cache (LLC) slice has a blended Caching and Home Agent (CHA), which gives scalability of sources all through the mesh for Intel® Extraordinarily Path Interconnect (Intel® UPI) cache coherency efficiency with none hotspots (Decide 1). Due to this each computes and HBM tile is a NUMA space with associated native memory, which supplies functions the facility to attenuate the information movement all through the chip and subsequently enhance effectivity.
Merchandise based mostly totally on modular semiconductor design and manufacturing are literally coming into the market. This suggests we’re capable of now take into account accelerated processor designs which will tempo frequently carried out operations (paying homage to small tensor operations) and offload a variety of housekeeping duties like zeroing memory and performing CRC calculations. Even greater, we’re capable of now moreover take into account some great benefits of faster HBM on data-intensive workloads along with the flexibility and effectivity benefits accrued when these accelerated cores are equipped with additional info per unit of time. Up to now, the outcomes are terribly encouraging.
Rob Farber is a know-how information and creator with an in depth background in HPC and machine finding out know-how.
[1] See moreover Getting Further Out of Every Extreme Effectivity Computing Core
[2] See [N18] at http://intel.com/processorclaims : 4th Gen Intel® Xeon® Scalable processors. Outcomes might vary.
[3] https://www.nextplatform.com/2023/01/16/application-acceleration-for-the-masses/
[4] https://www.intel.com/content material materials/www/us/en/newsroom/info/4th-gen-xeon-scalable-processors-max-series-cpus-gpus.html
[5] https://cdrdv2-public.intel.com/759709/353216-data-streaming-accelerator-user-guide-2.pdf
[6] https://dsatutorial.web.illinois.edu/
[7] See [N18] at http://intel.com/processorclaims: 4th Gen Intel® Xeon® Scalable processors. Outcomes might vary.
[8]See slide 8 in https://www.colfax-intl.com/downloads/Public-Accelerators-Deep-Dive-Presentation-Intel-DSA.pdf
[9] https://en.wikipedia.org/wiki/High_Bandwidth_Memory
[10] LAMMPS (Atomic Fluid, Copper, DPD, Liquid_crystal, Polyethylene, Protein, Stillinger-Weber, Tersoff, Water)
Intel® Xeon® 8380: Check out by Intel as of 10/11/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Full Memory 256 GB (16x16GB 3200MT/s, Twin-Rank), BIOS Mannequin SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:on; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=extreme;
Intel® Xeon® 8480+: Check out by Intel as of 9/29/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Full Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Mannequin SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:off; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=extreme;
Intel® Xeon® Max 9480: Check out by Intel as of 9/29/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Full Memory 128 GB (HBM2e at 3200 MHz), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, LAMMPS v2021-09-29 cmkl:2022.1.0, icc:2021.6.0, impi:2021.6.0, tbb:2021.6.0; threads/core:; Turbo:off; BuildKnobs:-O3 -ip -xCORE-AVX512 -g -debug inline-debug-info -qopt-zmm-usage=extreme;
DeePMD (Multi-Event Teaching)
Intel® Xeon® 8380: Check out by Intel as of 10/20/2022. 1-node, 2x Intel® Xeon® 8380 processor, Full Memory 256 GB, kernel 4.18.0-372.26.1.eI8_6.crt1.x86_64, compiler gcc (GCC) 8.5.0 20210514 (Crimson Hat 8.5.0-10), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
3.9
Intel® Xeon® 8480+: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, Full Memory 512 GB, kernel 4.18.0-365.eI8_3x86_64, compiler gcc (GCC) 8.5.0 20210514 (Crimson Hat 8.5.0-10), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
Intel® Xeon® Max 9480: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, Full Memory 128 GB (HBM2e at 3200 MHz), kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Crimson Hat 8.5.0-13), https://github.com/deepmodeling/deepmd-kit, Tensorflow 2.9, Horovod 0.24.0, oneCCL-2021.5.2, Python 3.9
Quantum Espresso (AUSURF112, Water_EXX)
Intel® Xeon® 8380: Check out by Intel as of 9/30/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Full Memory 256 GB (16x16GB 3200MT/s, Twin-Rank), ucode revision=0xd000375, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, Quantum Espresso 7.0, AUSURF112, Water_EXX
Intel® Xeon® 8480+: Check out by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Full Memory 512 GB (16x32GB 4800MT/s, Twin-Rank), ucode revision= 0x90000c0, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, Quantum Espresso 7.0, AUSURF112, Water_EXX
Intel® Xeon® Max 9480: Check out by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Full Memory 128 GB (8x16GB HBM2 3200MT/s), ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, Quantum Espresso 7.0, AUSURF112, Water_EXX
ParSeNet (SplineNet)
Intel® Xeon® 8380: Check out by Intel as of 10/18/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Full Memory 256 GB (16x16GB 3200MT/s, Twin-Rank), BIOS Mannequin SE5C6200.86B.0020.P23.2103261309, ucode revision=0xd000270, Rocky Linux 8.6, Linux mannequin 4.18.0-372.19.1.el8_6.crt1.x86_64, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
Intel® Xeon® 8480+: Check out by Intel as of 10/18/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Full Memory 512 GB (16x32GB 4800MT/s, Twin-Rank), BIOS Mannequin EGSDCRB1.86B.0083.D22.2206290535, ucode revision=0xaa0000a0, CentOS Stream 8, Linux mannequin 4.18.0-365.el8.x86_64, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
Intel® Xeon® Max 9480: Check out by Intel as of 09/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Full Memory 128 GB (8x16GB HBM2 3200MT/s), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (20220804), oneDNN (v2.6.0)
CosmoFlow (teaching on 8192 image batches)
third Gen Intel® Xeon® Scalable Processor 8380 : Check out by Intel as of 06/07/2022. 1-node, 2x Intel® Xeon® Scalable Processor 8380, 40 cores, HT On, Turbo On, Full Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS SE5C6200.86B.0022.D64.2105220049, ucode 0xd0002b1, OS Crimson Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, https://github.com/mlcommons/hpc/tree/vital/cosmoflow, AVX-512, FP32, Tensorflow 2.9.0, horovod 0.23.0, keras 2.6.0, oneCCL-2021.4, oneAPI MPI 2021.4.0, ppn=8, LBS=16, ~25GB info, 16 epochs, Python 3.8
Intel® Xeon® 8480+ (AVX-512 FP32): Check out by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Xeon 8480+, HT On, Turbo On, Full Memory 512 GB (16 slots/ 32 GB/ 4800 MHz, DDR5), BIOS EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel 4.18.0-365.el8.x86_64, https://github.com/mlcommons/hpc/tree/vital/cosmoflow, AVX-512, FP32, Tensorflow 2.6.0, horovod 0.23, keras 2.6.0, oneCCL 2021.5, ppn=8, LBS=16, ~25GB info, 16 epochs, Python 3.8
Intel® Xeon® Processor Max Sequence HBM (AVX-512 FP32): Check out by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, Full Memory 128 HBM and 512 GB DDR (16 slots/ 32 GB/ 4800 MHz), BIOS SE5C7411.86B.8424.D03.2208100444, ucode 0x2c000020, CentOS Stream 8, kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, https://github.com/mlcommons/hpc/tree/vital/cosmoflow, AVX-512, FP32, TensorFlow 2.6.0, horovod 0.23.0, keras 2.6.0, oneCCL 2021.5, ppn=8, LBS=16, ~25GB info, 16 epochs, Python 3.8
Intel® Xeon® 8480+ (AMX BF16): Check out by Intel as of 10/18/2022. 1node, 2x Intel® Xeon® Platinum 8480+, HT On, Turbo On, Full Memory 512 GB (16 slots/ 32 GB/ 4800 MHz, DDR5), BIOS EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel 4.18.0-365.el8.x86_64, https://github.com/mlcommons/hpc/tree/vital/cosmoflow, AMX, BF16, Tensorflow 2.9.1, horovod 0.24.3, keras 2.9.0.dev2022021708, oneCCL 2021.5, ppn=8, LBS=16, ~25GB info, 16 epochs, Python 3.8
Intel® Xeon® Max 9480 (AMX BF16): Check out by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, Full Memory 128 HBM and 512 GB DDR (16 slots/ 32 GB/ 4800 MHz), BIOS SE5C7411.86B.8424.D03.2208100444, ucode 0x2c000020, CentOS Stream 8, kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, https://github.com/mlcommons/hpc/tree/vital/cosmoflow, AMX, BF16, TensorFlow 2.9.1, horovod 0.24.0, keras 2.9.0.dev2022021708, oneCCL 2021.5, ppn=8, LBS=16, ~25GB info, 16 epochs, Python 3.9
DeepCAM
Intel® Xeon® Scalable Processor 8380: Check out by Intel as of 04/07/2022. 1-node, 2x Intel® Xeon® 8380 processor, HT On, Turbo Off, Full Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS SE5C6200.86B.0022.D64.2105220049, ucode 0xd0002b1, OS Crimson Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, compiler gcc (GCC) 8.5.0 20210514 (Crimson Hat 8.5.0-4), https://github.com/mlcommons/hpc/tree/vital/deepcam, torch1.11.0a0+git13cdb98, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB info, 16 epochs, Python3.8
Intel® Xeon® Max 9480 (Cache Mode) AVX-512: Check out by Intel as of 05/25/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On,Turbo Off, Full Memory 128GB HBM and 1TB (16 slots/ 64 GB/ 4800 MHz, DDR5), Cluster Mode: SNC4, BIOS EGSDCRB1.86B.0080.D05.2205081330, ucode 0x8f000320, OS CentOS Stream 8, kernel 5.18.0-0523.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Crimson Hat 8.5.0-10, https://github.com/mlcommons/hpc/tree/vital/deepcam, torch1.11.0a0+git13cdb98, AVX-512, FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB info, 16 epochs, Python3.8
Intel® Xeon® Max 9480 (Cache Mode) BF16/AMX: Check out by Intel as of 05/25/2022. 1-node, 2x Intel® Xeon® Max 9480 , HT On, Turbo Off, Full Memory 128GB HBM and 1TB (16 slots/ 64 GB/ 4800 MHz, DDR5), Cluster Mode: SNC4, BIOS EGSDCRB1.86B.0080.D05.2205081330, ucode 0x8f000320, OS CentOS Stream 8, kernel 5.18.0-0523.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Crimson Hat 8.5.0-10), https://github.com/mlcommons/hpc/tree/vital/deepcam, torch1.11.0a0+git13cdb98, AVX-512 FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512, AMX, BFloat16 Enabled), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB info, 16 epochs, Python3.8
Intel® Xeon® 8480+s Mulit-Node cluster: Check out by Intel as of 04/09/2022. 16-nodes Cluster, 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Full Memory 256 GB (16 slots/ 16 GB/ 4800 MHz, DDR5), BIOS Intel SE5C6301.86B.6712.D23.2111241351, ucode 0x8d000360, OS Crimson Hat Enterprise Linux 8.4 (Ootpa), kernel 4.18.0-305.el8.x86_64, compiler gcc (GCC) 8.4.1 20200928 (Crimson Hat 8.4.1-1), https://github.com/mlcommons/hpc/tree/vital/deepcam, torch1.11.0a0+git13cdb98 AVX-512, FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=4, LBS=16, ~1024GB info, 16 epochs, Python3.8
WRF4.4 – CONUS-2.5km
Intel Xeon 8360Y: Check out by Intel as of two/9/23, 2x Intel Xeon 8360Y, HT On, Turbo On, NUMA configuration SNC2, 256 GB (16x16GB 3200MT/s, Twin-Rank), BIOS Mannequin SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, WRF v4.4 constructed with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags ”-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Materials
Intel Xeon 8480+: Check out by Intel as of two/9/23, 2x Intel Xeon 8480+, HT On, Turbo On, NUMA configuration SNC4, 512 GB (16x32GB 4800MT/s, Twin-Rank), BIOS Mannequin SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, WRF v4.4 constructed with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Materials
Intel Xeon Max 9480: Check out by Intel as of two/9/23, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, 128 GB HBM2e at 3200 MHz and 512 GB DDR5-4800, BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, WRF v4.4 constructed with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -xCORE-AVX512 -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low -w -ftz -align array64byte -fno-alias -fimf-use-svml=true -inline-max-size=12000 -inline-max-total-size=30000 -vec-threshold0 -qno-opt-dynamic-align ”. HDR Materials
ROMS (benchmark3 (2048x256x30), benchmark3 (8192x256x30))
Intel® Xeon® 8380: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Full Memory 256 GB (16x16GB 3200MT/s, Twin-Rank), BIOS Mannequin SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, ROMS V4 assemble with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=extreme -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
Intel® Xeon® 8480+: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, NUMA configuration SNC4, Full Memory 512 GB (16x32GB 4800MT/s, Twin-Rank), BIOS Mannequin SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, ROMS V4 assemble with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=extreme -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
Intel® Xeon® Max 9480: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Full Memory 128 GB (HBM2e at 3200 MHz), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, ROMS V4 assemble with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-ip -O3 -heap-arrays -xCORE-AVX512 -qopt-zmm-usage=extreme -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, ROMS V4
NEMO (GYRE_PISCES_25, BENCH ORCA-1)
Intel® Xeon® 8380: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Full Memory 256 GB (16x16GB 3200MT/s, Twin-Rank), BIOS Mannequin SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, NEMO v4.2 assemble with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags ”-i4 -r8 -O3 -fno-alias -march=core-avx2 -fp-model fast=2 -no-prec-div -no-prec-sqrt -align array64byte -fimf-use-svml=true”
Intel® Xeon® Max 9480: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Full Memory 128 GB (HBM2e at 3200 MHz), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, NEMO v4.2 assemble with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-i4 -r8 -O3 -fno-alias -march=core-avx2 -fp-model fast=2 -no-prec-div -no-prec-sqrt -align array64byte -fimf-use-svml=true”.
Ansys Fluent
Intel Xeon 8380: Check out by Intel as of 08/24/2022, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Hemisphere, 256 GB DDR4-3200, BIOS Mannequin SE5C620.86B.01.01.0006.2207150335, ucode 0xd000375, Rocky Linux 8.7, kernel mannequin 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1 . HDR Materials
Intel Xeon 8480+: Check out by Intel as of two/11/2023, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4 Mode, 512 GB DDR5-4800, BIOS Mannequin SE5C7411.86B.8901.D03.2210131232, ucode 0x2b0000a1, Rocky Linux 8.7, kernel mannequin 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1. HDR Materials
Intel Xeon Max 9480: Check out by Intel as of 02/15/2023, 2x Intel Xeon Max 9480, HT ON, Turbo ON, SNC4, SNC4 and Fake Numa for Cache Mode runs, 128 GB HBM2e at 3200 MHz and 512 GB DDR5-4800, BIOS Mannequin SE5C7411.86B.9409.D04.2212261349, ucode 0xac000100, Rocky Linux 8.7, kernel mannequin 4.18.0-372.32.1.el8_6.crt2.x86_64, Ansys Fluent 2022R1. HDR Materials
Ansys LS-DYNA (ODB-10M)
Intel® Xeon® 8380: Check out by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Full Memory 256 GB (16x16GB 3200MT/s DDR4), BIOS Mannequin SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, LS-DYNA R11
Intel® Xeon® 8480+: Check out by Intel as of ww41’22. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Full Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Mannequin SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, LS-DYNA R11
Intel® Xeon® Max 9480: Check out by Intel as of ww36’22. 1-node, 2x Intel® Xeon® Max 9480, HT
Ansys Mechanical (V22iter-1, V22iter-2, V22iter-3, V22iter-4, V22direct-1, V22direct-2, V22direct-3)
Intel® Xeon® 8380: Check out by Intel as of 08/24/2022. 1-node, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Quad, Full Memory 256 GB, BIOS Mannequin SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel mannequin 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Mechanical 2022 R2
AMD EPYC 7763: Check out by Intel as of 8/24/2022. 1-node, 2x AMD EPYC 7763, HT On, Turbo On, NPS2,Full Memory 512 GB, BIOS ver. Ver 2.1 Rev 5.22, ucode 0xa001144, Rocky Linux 8.6, kernel mannequin 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Mechanical 2022 R2
AMD EPYC 7773X: Check out by Intel as of 8/24/2022. 1-node, 2x AMD EPYC 7773X, HT On, Turbo On, NPS4,Full Memory 512 GB, BIOS ver. M10, ucode 0xa001229, CentOS Stream 8, kernel mannequin 4.18.0-383.el8.x86_6, Ansys Mechanical 2022 R2
Intel® Xeon® 8480+: Check out by Intel as of 09/02/2022. 1-node, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4, Full Memory 512 GB DDR5 4800 MT/s, BIOS Mannequin EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel mannequin 4.18.0-365.el8.x86_64, Ansys Mechanical 2022 R2
Intel® Xeon® Max 9480: Check out by Intel as of 08/31/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo ON, SNC4, Full Memory 512 GB DDR5 4800 MT/s, 128 GB HBM in Cache Mode (HBM2e at 3200 MHz), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode 2c000020, CentOS Stream 8, kernel mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, Ansys Mechanical 2022 R2
Altair AcuSolve (HQ Model)
Intel® Xeon® 8380: Check out by Intel as of 09/28/2022. 1-node, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Quad, Full Memory 256 GB, BIOS Mannequin SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel mannequin 4.18.0-372.19.1.el8_6.crt1.x86_64, Altair AcuSolve 2021R2
Intel® Xeon® 6346: Check out by Intel as of 10/08/2022. 4-nodes associated by the use of HDR-200, 2x Intel® Xeon® 6346, 16 cores, HT ON, Turbo ON, Quad, Full Memory 256 GB, BIOS Mannequin SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel mannequin 4.18.0-372.19.1.el8_6.crt1.x86_64, Altair AcuSolve 2021R2
Intel® Xeon® 8480+: Check out by Intel as of 09/28/2022. 1-node, 2x Intel® Xeon® 8480+, HT ON, Turbo ON, SNC4, Full Memory 512 GB, BIOS Mannequin EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel mannequin 4.18.0-365.el8.x86_64, Altair AcuSove 2021R2
Intel® Xeon® Max 9480: Check out by Intel as of 10/03/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, SNC4, Full Memory 128 GB (HBM2e at 3200 MHz), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode 2c000020, CentOS Stream 8, kernel mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, Altair AcuSolve 2021R2
OpenFOAM (Geomean of Motorbike 20M, Motorbike 42M)
Intel® Xeon® 8380: Check out by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, Full Memory 256 GB (16x16GB 3200MT/s, Twin-Rank), BIOS Mannequin SE5C6200.86B.0020.P23.2103261309, ucode revision=0xd000270, Rocky Linux 8.6, Linux mannequin 4.18.0-372.19.1.el8_6.crt1.x86_64, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
Intel® Xeon® 8480+: Check out by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, Full Memory 512 GB (16x32GB 4800MT/s, Twin-Rank), BIOS Mannequin EGSDCRB1.86B.0083.D22.2206290535, ucode revision=0xaa0000a0, CentOS Stream 8, Linux mannequin 4.18.0-365.el8.x86_64, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
Intel® Xeon® Max 9480: Check out by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT On, Turbo On, SNC4, Full Memory 128 GB (8x16GB HBM2 3200MT/s), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, OpenFOAM 8, Motorbike 20M @ 250 iterations, Motorbike 42M @ 250 iterations
MPAS-A (MPAS-A V7.3 60-km dynamical core)
Intel® Xeon® 8380: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Full Memory 256 GB (16x16GB 3200MT/s, Twin-Rank), BIOS Mannequin SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, MPAS-A V7.3 assemble with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
Intel® Xeon® 8480+: Check out by Intel as of 10/12/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, NUMA configuration SNC4, Full Memory 512 GB (16x32GB 4800MT/s, Twin-Rank), BIOS Mannequin SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, MPAS-A V7.3 assemble with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
Intel® Xeon® Max 9480: Check out by Intel as of 10/12/22. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Full Memory 128 GB (HBM2e at 3200 MHz), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, MPAS-A V7.3 assemble with Intel® Fortran Compiler Conventional and Intel® MPI from 2022.3 Intel® oneAPI HPC Toolkit with compiler flags “-O3 -march=core-avx2 -convert big_endian -free -align array64byte -fimf-use-svml=true -fp-model fast=2 -no-prec-div -no-prec-sqrt -fimf-precision=low”, MPAS-A V7.3
GROMACS (benchMEM, benchPEP, benchPEP-h, benchRIB, hecbiosim-3m, hecbiosim-465k, hecbiosim-61k, ion_channel_pme_large, lignocellulose_rf_large, rnase_cubic, stmv, water1.5M_pme_large, water1.5M_rf_large)
Intel® Xeon® 8380: Check out by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8380 CPU, HT On, Turbo On, NUMA configuration SNC2, Full Memory 256 GB (16x16GB 3200MT/s, Twin-Rank), BIOS Mannequin SE5C620.86B.01.01.0006.2207150335, ucode revision=0xd000375, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, Converge GROMACS v2021.4_SP
Intel® Xeon® 8480+: Check out by Intel as of 10/7/2022. 1-node, 2x Intel® Xeon® 8480+, HT On, Turbo On, SNC4, Full Memory 512 GB (16x32GB 4800MT/s, DDR5), BIOS Mannequin SE5C7411.86B.8713.D03.2209091345, ucode revision=0x2b000070, Rocky Linux 8.6, Linux mannequin 4.18.0-372.26.1.el8_6.crt1.x86_64, GROMACS v2021.4_SP
Intel® Xeon® Max 9480: Check out by Intel as of 9/2/2022. 1-node, 2x Intel® Xeon® Max 9480, HT ON, Turbo ON, NUMA configuration SNC4, Full Memory 128 GB (HBM2e at 3200 MHz), BIOS Mannequin SE5C7411.86B.8424.D03.2208100444, ucode revision=0x2c000020, CentOS Stream 8, Linux mannequin 5.19.0-rc6.0712.intel_next.1.x86_64+server, GROMACS v2021.4_SP




